
Redis 提供了两种持久化的方式,分别是 RDB(Redis DataBase)和 AOF(Append Only File)
RDB 简而言之,就是在不同的时间点,将 redis 存储的数据生成快照并存储到磁盘等介质上
AOF 则是换了一个角度来实现持久化,那就是将 Redis 执行过的所有写指令记录下来,在下次 Redis 重新启动时,只要把这些写指令从前到后再重复执行一遍,就可以实现数据恢复了
其实 RDB 和 AOF 两种方式也可以同时使用,在这种情况下,如果 Redis 重启的话,则会优先采用 AOF 方式来进行数据恢复,这是因为 AOF 方式的数据恢复完整度更高
如果你没有数据持久化的需求,也完全可以关闭 RDB 和 AOF 方式,这样的话,redis 将变成一个纯内存数据库,就像 memcache 一样
RDB 使用方式
Redis 提供了两个命令来生成 RDB 文件,分别是 save 和 bgsave,他们的区别就在于是否在「主线程」里执行
- save:会在主线程生成 RDB 文件,由于和执行操作命令在同一个线程,所以如果写入 RDB 文件的时间太长,会阻塞主线程
- bgsave:会创建一个子进程来生成 RDB 文件,这样可以避免主线程的阻塞
RDB 文件的加载工作是在服务器启动时自动执行的,Redis 并没有提供专门用于加载 RDB 文件的命令
Redis 还可以通过配置文件的选项来实现每隔一段时间自动执行一次 bgsave 命令,默认会提供以下配置
1 | save 900 1 |
虽然这里配置名为
save,但实际上执行的是 bgsave 命令意思是,只要满足了下面任意条件就会执行 bgsave
- 900 秒(15分钟)内有 1 个更改
- 300 秒(5分钟)内有 10 个更改
- 60 秒内有 10000 个更改
因为 Redis 的快照是全量快照,也就是说每次执行快照,都是把内存中的「所有数据」都记录到磁盘中
所以可以认为,执行快照是一个比较重的操作,如果频率太频繁,可能会对 Redis 性能产生影响。如果频率太低,服务器故障时,丢失的数据会更多
通常可能设置至少 5 分钟才保存一次快照,这时如果 Redis 出现宕机等情况,则意味着最多可能丢失 5 分钟数据
这就是 RDB 快照的缺点,在服务器发生故障时,丢失的数据会比 AOF 持久化的方式更多,因为 RDB 快照是全量快照的方式,因此执行的频率不能太频繁,否则会影响 Redis 性能,而 AOF 日志可以以秒级的方式记录操作命令,所以丢失的数据就相对更少
自动触发 RDB
除了上面提到的,满足 redis.conf 配置时自动触发外,另外三种情况下也会自动触发执行 bgsave
- 主从复制时,从节点要从主节点进行全量复制时也会触发 bgsave 操作,生成当时的快照发送给从节点
- 执行
debug reload时,重新加载 Redis 时也会触发 bgsave 操作 - 默认情况下执行
shutdown命令时,如果没有开启 AOF 持久化,也会触发 bgsave 操作
RDB 相关配置
1 | # 文件名称 |
- dbfilename:RDB 文件在磁盘上的名称
- dir:RDB 文件的存储路径
- stop-writes-on-bgsave-error:使用 bgsave 生成快照的过程中,主进程照样可以接受客户端的任何写操作的特性,这时如果快照操作出现异常(例如操作系统用户权限不够、磁盘空间写满等等)时,Redis就会禁止写操作
- rdbcompression:该属性将在字符串类型的数据被快照到磁盘文件时,启用LZF压缩算法
- rdbchecksum:RDB 快照功能从 version 5 开始,在RDB文件的末尾增加一个 64 位的 CRC 冗余校验编码,以便对整个 RDB 文件的完整性进行验证。这个功能大概会损失 10% 左右的性能,但获得了更高的数据可靠性。如果需要追求极致的性能,可以将这个选项设置为 no
bgsave 执行过程
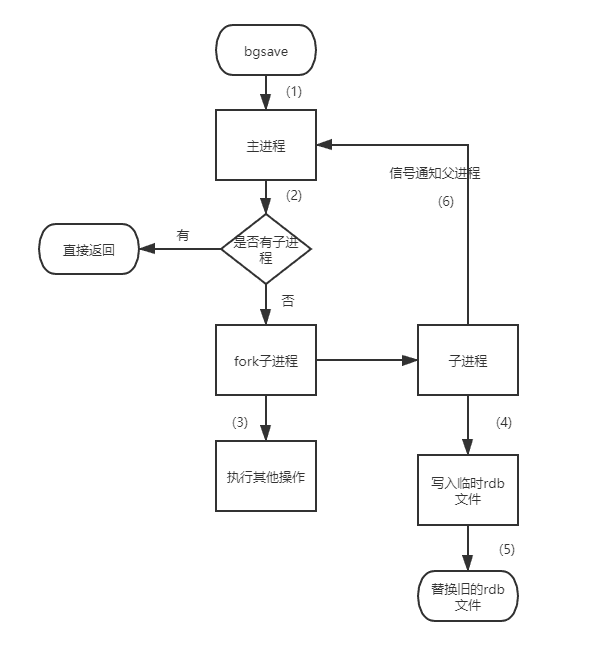
- Redis 客户端执行 bgsave 命令或者自动触发 bgsave
- 主线程判断当前是否已存在正在执行的子进程,如果存在,主进程直接返回
- 如果不存在正在执行的子进程,那么就 fork 一个新的子进程进行持久化数据,fork 的过程是阻塞的,fork 完成后主进程即可执行其他操作
- 子进程先将数据写到临时的 rdb 文件中,待快照数据写入完成后,再替换旧的 rdb 文件
- 发送信号给主进程,通知主进程 rdb 持久化完成,主进程更新相关的统计信息(info Persitence 下的 rdb_* 相关选项)
深入理解 RDB
从实际出发,深入理解 RDB
快照过程中修改数据
执行 bgsave 过程中,由于是交给子进程来构建 RDB 文件,主线程还是可以继续工作的,那么问题来了,此时主进程如果修改了数据,该如何处理?
如果不允许修改的话,那性能就会大幅下降
如果允许修改的话,该如何处理这个过程呢
实现的关键就在于「Copy-On-Write」(类似 java 中的 CopyOnWriteArrayList)
在执行 bgsave 的时候,会通过 fork 创建子进程,此时主进程和子进程都是共享一片内存的,因为创建子进程的时候,会复制主进程的页表,而页表指向的物理内存是同一个
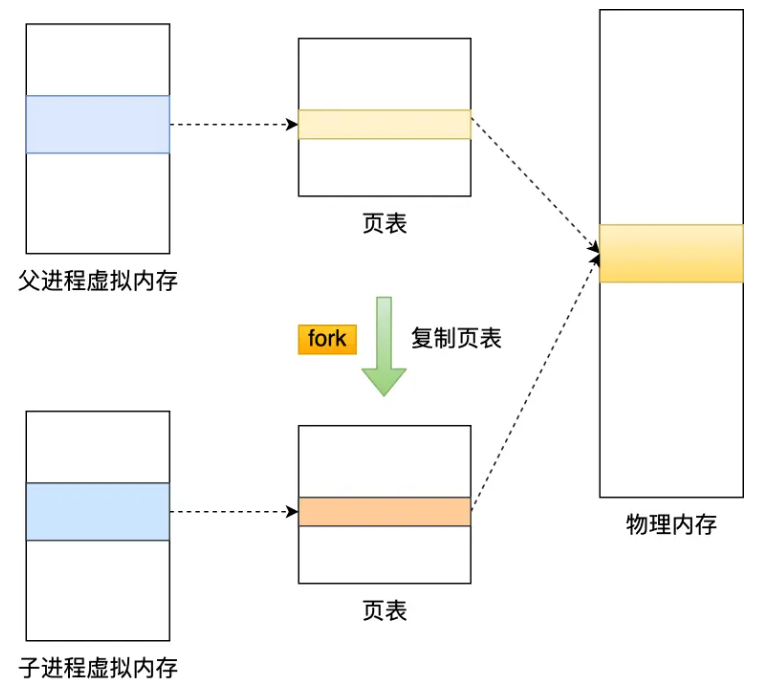
当主进程发生修改时,复制一份物理内存
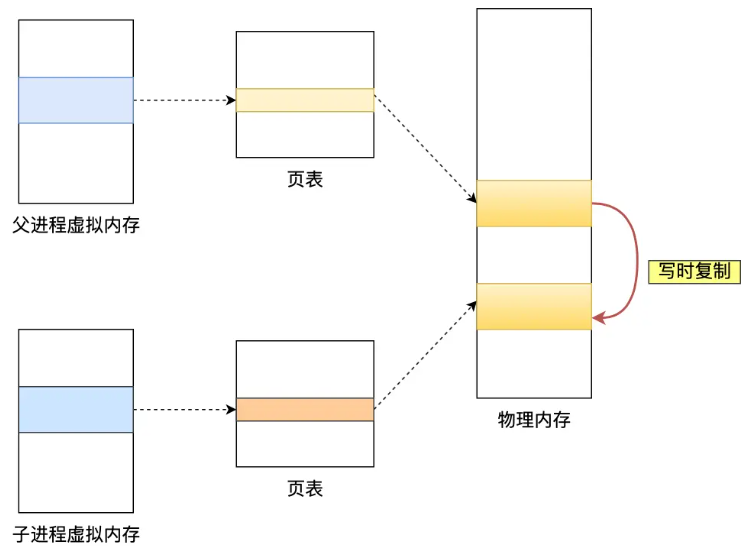
这样可以有效地减少创建子进程时的性能损耗,从而加快子进程的创建,毕竟创建子进程的过程是阻塞的
当 bgsave 创建完子进程后,由于共享主进程的所有内存数据,所以可以直接读取主进程的数据然后写入到 RDB 文件内
如果在这期间主进程都是只读操作,那么主进程和子进程互不影响
如果在这期间主进程发生了增删改操作,就会出现 Copy-On-Write
- 先将待操作数据对应的物理内存进行复制
- 然后主进程对复制的数据副本进行操作
- 与此同时,子进程将原始数据写入 RDB 内
可以看出,如果主进程在 bgsave 生成快照期间发生了增删改操作,那么新的数据是没有写入到 RDB 内的,RDB 内的数据为操作前的原始数据,而新数据只能等下次 RDB 快照写入
快照过程中服务崩溃
在没有将数据全部写入到磁盘前,这次的快照都不算成功
RDB 快照时会创建一个临时文件进行操作,待操作全部成功后,才会将这个临时文件替换掉上次的快照文件
如果在快照过程中服务发生了崩溃,将以上次完整的 RDB 快照文件作为恢复内存数据的参考
频繁的快照
由👆可知,如果在 T0 时刻做了一个快照,然后修改了某些数据,这时在 T0+t 时刻再做一次快照,但是如果 T0+t 这次快照失败了,那么只能恢复到 T0 时刻,也就是说这里的 某些数据 就丢失了
这时,如果提高快照的频率,在 T0 到 T0+t 这个时间段内多做几次快照,是不是能减少丢失的数据呢?
这只是理论上的可能,实际并非如此
- 快照是针对全量的数据进行操作,如果频繁的快照,会增加磁盘的 io,影响整个机器的性能
- 虽然 bgsave 主要是子进程进行快照,但 fork 过程是会阻塞主进程的,频繁快照会频繁阻塞主进程,影响服务性能
- 快照过程中的修改是通过 Copy-On-Write 的机制来保证高性能的,如果频繁快照,那么就可能会多出很多数据副本,会占用大量的内存
正确的处理方式应该是使用 RDB 与 AOF 结合的方式
RDB 的优缺点
优点
- 快速恢复:由于 RDB 文件是快照,恢复速度非常快
- 紧凑的数据文件:RDB 文件是采用 LZF 算法压缩后的二进制文件,非常紧凑,占用的磁盘空间相对较小,适合长期存储
缺点
- 数据丢失风险:RDB 持久化是周期性的,通常按照配置的时间间隔触发。在两次持久化之间,如果 Redis 发生故障,可能会导致数据丢失
- 大数据集的性能问题:大型数据集上执行 RDB 持久化可能会导致 Redis 在持久化期间出现性能下降,因为需要将整个数据库写入磁盘。如果 Redis 正在处理大量写操作,RDB 持久化可能会产生性能问题,因为快照可能会占用大量的 CPU 和 I/O 资源
- 缺乏可读性:由于 RDB 文件是二进制的,没有可读性,AOF 文件在了解其结构的情况下可以手动修改或者补全
由于 RDB 不适合实时持久化存在丢失数据的风险,所以 Redis 还提供了 AOF 持久化的方式来解决