
redis 除了
string、hash、list、set、zset这五种基础类型外,还有四种较为特殊的类型
BitMap
位图,是一串连续的二进制数组(0 和 1),可以通过偏移量(offset)定位元素。BitMap 通过最小的单位 bit 来进行
0|1的设置,表示某个元素的值或者状态
Bitmap 本身是用 String 类型作为底层数据结构实现的一种统计二值状态的数据类型
String 类型是会保存为二进制的字节数组,所以,Redis 就把字节数组的每个 bit 位利用起来,用来表示一个元素的二值状态,可以把 Bitmap 看作是一个 bit 数组
SETBIT
语法规则:SETBIT key offset value
对 key 所储存的字符串值,设置或清除指定 offset 上的位(bit)
根据 value 是 1 或 0 来决定设置或清除 bit
0 ≤ offset ≤ 2^32
1 | > setbit venom:bit 0 1 |
返回的是存储在 offset 位置上原来的值
GETBIT
语法规则:GETBIT key offset
获取指定 offset 位置上的 bit
如果 offset 比字符串的长度大,则返回 0
1 | > getbit venom:bit 0 |
BITCOUNT
语法规则:BITCOUNT key [start end]
统计字符串被设置为 1 的 bit 数
start 和 end 的第一位为 0,最后一位为 -1
start 和 end 为空时,统计整个字符串
1 | > bitcount venom:bit |
BITFIELD
语法规则:BITFIELD key [GET type offset] [SET type offset value] [INCRBY type offset increment] [OVERFLOW WRAP|SAT|FAIL]
- [GET type offset]:用于获取指定位上的值
- type:要获取值得类型,可以是
u8、u16、u32、i5(无符号8、16、32位整数或有符号5位整数) - offset:要获取的位的偏移量
- type:要获取值得类型,可以是
- [SET type offset value]:用于设置指定位的值
- type:同上
- offset:要设置的位的偏移量
- value:要设置的值
- [INCRBY type offset increment]:用于增减指定位上的值
- type:同上
- offset:要增减位的偏移量
- increment:增减幅度
- [OVERFLOW WRAP|SAT|FAIL]:用于指定溢出的处理方式
- WRAP:循环溢出,比如说,如果我们对一个值为 127 的 i8 整数执行加一操作,那么将得到结果 -128
- SAT:饱和溢出,比如说,如果我们对一个值为 127 的 i8 整数执行加一操作,那么将为 i8 类型所能储存的最大整数值 127
- FAIL:失败,拒绝执行那些会导致上溢或者下溢情况出现的计算,并向用户返回空值表示计算未被执行
BITFIELD 允许在字符串中执行多个位操作,如设置、获取和增减指定位的值
1 | # 给 venom:bit2 设置一个偏移量为 7 的 5 位无符号整数 23(10111) |
将十六进制的 \x01p 转为二进制字符串
十六进制的 01 转为二进制为:00000001
p 的 ASCII 值为 112 转为二进制为:01110000
Java 转换代码:
1 | public class HexToBinary { |
BITOP
语法规则:BITOP operation destkey key [key ...]
BITOP AND destkey srckey1 srckey2 srckey3 ... srckeyN对一个或多个 key 求逻辑与,并将结果保存到 destkeyBITOP OR destkey srckey1 srckey2 srckey3 ... srckeyN对一个或多个 key 求逻辑或,并将结果保存到 destkeyBITOP NOT destkey srckey对给定 key 求逻辑非,并将结果保存到 destkeyBITOP XOR destkey srckey1 srckey2 srckey3 ... srckeyN对一个或多个 key 求逻辑异或,并将结果保存到 destkey
注:除了 NOT 操作之外,其他操作都可以接受一个或多个 key 作为输入。保存到 destkey 的字符串的长度,和输入 key 中最长的字符串长度相等
1 | > set venom:bit3 abcdef |
BITPOS
语法规则:BITPOS key bit [start] [end]
返回字符串里面第一个被设置为 1 或者 0 的 bit 位
默认情况下整个字符串都会被检索一次,只有在指定 start 和 end 参数,该范围被解释为一个字节的范围,而不是一系列的位。所以 start=0 并且 end=2 是指前三个字节范围内查找
1 | # 设置:111111111111000000000000 |
应用场景
- 签到打卡:Bitmap 类型非常适合二值状态统计的场景,在记录海量数据时,Bitmap 能够有效地节省内存空间
HyperLogLog
HyperLogLog 是 Redis 2.8.9 版本新增的数据类型,是一种用于「统计基数」的数据集合类型,基数统计就是指统计一个集合中不重复的元素个数。但要注意,HyperLogLog 是统计规则是基于概率完成的,不是非常准确,标准误算率是 0.81%
什么是基数:比如数据集
{1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为{1, 3, 5 ,7, 8}, 基数(不重复元素)为 5。 基数估计就是在误差可接受的范围内,快速计算基数
HyperLogLog 的优势在于只需要花费 12 KB 内存,就可以计算接近 2^64 个元素的基数,和元素越多就越耗费内存的 Set 和 Hash 类型相比,HyperLogLog 就非常节省空间
因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素
PFADD
语法规则:PFADD key element [element ...]
将所有元素参数添加到 HyperLogLog 数据结构中
如果 HyperLogLog 估计的近似基数(approximated cardinality)在命令执行之后出现了变化,那么命令返回 1, 否则返回 0
1 | > pfadd venom:hll a |
PFCOUNT
语法规则:PFCOUNT key [key ...]
返回给定 HyperLogLog 的基数估算值
当 PFCOUNT 命令作用于单个键时,返回储存在给定键的 HyperLogLog 的近似基数, 如果键不存在, 那么返回 0
当 PFCOUNT 命令作用于多个键时, 返回所有给定 HyperLogLog 的并集的近似基数,这个近似基数是通过将所有给定 HyperLogLog 合并至一个临时 HyperLogLog 来计算得出的
1 | > pfcount venom:hll |
PFMERGE
语法规则:PFMERGE destkey sourcekey [sourcekey ...]
将多个 HyperLogLog 合并为一个 HyperLogLog,合并后的 HyperLogLog 的基数估算值是通过对所有给定 HyperLogLog 进行并集计算得出的
1 | > pfadd venom:hll2 1 2 3 4 0 1 2 3 4 |
应用场景
- 百万级网页 UV 计数:在统计 UV 时,你可以用 PFADD 命令把访问页面的每个用户都添加到 HyperLogLog 中,然后就可以用 PFCOUNT 命令直接获得 page1 的 UV 大概值了
GEO
GEO 是 Redis 3.2 版本新增的数据类型,主要用于存储地理位置信息,并对存储的信息进行操作
在日常生活中,我们越来越依赖搜索“附近的餐馆”、在打车软件上叫车,这些都离不开基于位置信息服务(Location-Based Service,LBS)的应用。LBS 应用访问的数据是和人或物关联的一组经纬度信息,而且要能查询相邻的经纬度范围,GEO 就非常适合应用在 LBS 服务的场景中
GEO 本身并没有设计新的底层数据结构,而是直接使用了 Sorted Set 集合类型
GEO 类型使用 GeoHash 编码方法实现了经纬度到 Sorted Set 中元素权重分数的转换,这其中的两个关键机制就是「对二维地图做区间划分」和「对区间进行编码」。一组经纬度落在某个区间后,就用区间的编码值来表示,并把编码值作为 Sorted Set 元素的权重分数
这样一来,我们就可以把经纬度保存到 Sorted Set 中,利用 Sorted Set 提供的“按权重进行有序范围查找”的特性,实现 LBS 服务中频繁使用的“搜索附近”的需求
GEOADD
语法规则:GEOADD key longitude latitude member [longitude latitude member ...]
存储指定的地理空间位置,可以将一个或多个经度(longitude)、纬度(latitude)、位置名称(member)添加到指定的 key 中
1 | # 深圳北站 深圳东站 深圳站 |
GEOPOS
语法规则:GEOPOS key member [member ...]
从给定的 key 里返回所有指定名称(member)的位置(经度和纬度),不存在的返回 nil
1 | > geopos venom:geo "Shenzhen Railway Station" |
GEODIST
语法规则:GEODIST key member1 member2 [m|km|ft|mi]
- m:米
- km:千米
- ft:英尺
- mi:英里
返回两个给定位置之间的距离
1 | # 深圳北站到深圳站的直线距离 |
GEORADIUS
语法规则:GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]
- WITHHASH:以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。 这个选项主要用于底层应用或者调试, 实际中的作用并不大
- WITHCOORD:将位置元素的经度和维度也一并返回
- WITHDIST:在返回位置元素的同时,将位置元素与中心之间的距离也一并返回
- COUNT:限定返回的记录数
- ASC:查找结果根据距离从近到远排序
- DESC:查找结果根据从远到近排序
以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素
1 | # 以 [114.069118,22.606168] 为中心搜索 5km 内的元素并返回元素与中心的距离 |
GEORADIUSBYMEMBER
语法规则:GEORADIUSBYMEMBER key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]
与 GEORADIUS 类似,不同的是,中心点是由元素决定的,而不是经纬度
1 | # 深圳南站 10km 内的元素 |
GEOHASH
语法规则:GEOHASH key member [member ...]
获取一个或多个位置元素的 geohash 值
1 | > geohash venom:geo "Shenzhen North Railway Station" "Shenzhen East Railway Station" "Shenzhen Railway Station" |
应用场景
- 地图两点间的距离
- 指定中心范围内的元素
Stream
Stream 是 Redis 5.0 版本新增加的数据类型,Redis 专门为消息队列设计的数据类型
在 Redis 5.0 Stream 没出来之前,消息队列的实现方式都有着各自的缺陷,例如:
- 发布订阅模式,不能持久化也就无法可靠的保存消息,并且对于离线重连的客户端不能读取历史消息的缺陷
- List 实现消息队列的方式不能重复消费,一个消息消费完就会被删除,而且生产者需要自行实现全局唯一 ID
基于以上问题,Redis 5.0 便推出了 Stream 类型也是此版本最重要的功能,用于完美地实现消息队列,它支持 消息的持久化、支持 自动生成全局唯一 ID、支持 ack 确认消息 的模式、支持 消费组模式 等,让消息队列更加的稳定和可靠
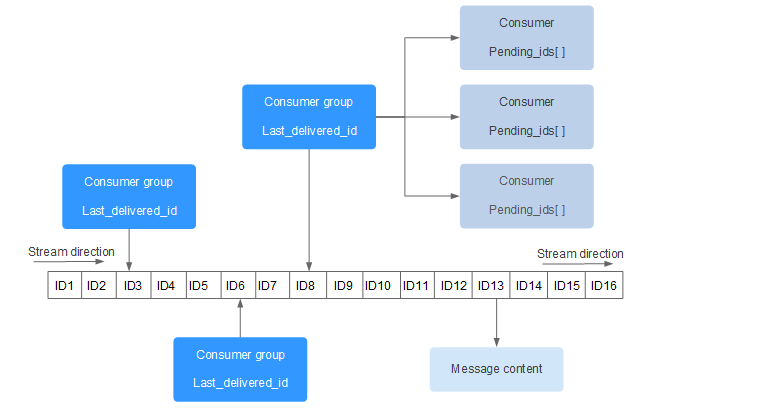
- Consumer group:消费组,使用
XGROUP CREATE命令创建,一个消费组有多个消费者(Consumer) - Last_delivered_id:游标,每个消费组会有一个游标,任意一个消费者读取了消息都会使游标往前移动
- Pending_ids:消费者的状态变量,记录了当前已经被客户端读取的消息,但是还没有 ack 的 id
每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用 xadd 指令追加消息时自动创建
XADD
语法规则:XADD key ID field value [field value ...]
- key:队列名称,如果不存在就创建
- ID:消息 id,我们使用 * 表示由 redis 生成,可以自定义,但是要自己保证递增性
- field value:键值对记录
向队列添加消息,如果指定的队列不存在,则创建一个队列
1 | > xadd venom:stream * s1 aaa s2 bbb s3 ccc |
XLEN
语法规则:XLEN key
获取流包含的元素数量,即消息长度
1 | > xlen venom:stream |
XRANGE
语法规则:XRANGE key start end [COUNT count]
- key:队列名称
- start:开始值,- 表示最小值
- end:结束值,+ 表示最大值
- count:数量
获取消息列表,会自动过滤已经删除的消息
1 | > xrange venom:stream - + |
XTRIM
语法规则:XTRIM key MAXLEN [~] count
- key:队列名称
- MAXLEN:长度
- count:数量
对流进行修剪,限制长度
1 | > xtrim venom:stream MAXLEN 2 |
XDEL
语法规则:XDEL key ID [ID ...]
- key:队列名称
- ID:消息 ID
删除消息
1 | > xdel venom:stream 1698057730446-0 |
XREVRANGE
语法规则:XREVRANGE key end start [COUNT count]
与 XRANGE 类似,获取消息列表,不过是倒序的
1 | > xadd venom:stream * name venom age 18 |
XREAD
语法规则:XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...]
- count:可选,读取数量,默认读取所有
- milliseconds:可选,阻塞毫秒数,默认是非阻塞式
- key:队列名称
- id:消息 ID
以阻塞或非阻塞方式获取消息
1 | > xread streams venom:stream 0-0 |
XGROUP CREATE
语法规则:XGROUP [CREATE key groupname id-or-$] [SETID key groupname id-or-$] [DESTROY key groupname] [DELCONSUMER key groupname consumername]
- key:队列名称,不存在则创建
- groupname:消费组名称
- $:从尾部开始消费,只接收新的消息
创建从头开始消费的消费者组(如同 kafka 中的 earliest)
1 | > xgroup create venom:stream consumer-group-earliest 0-0 |
创建从最新的消息开始消费的消费组(如同 kafka 中的 latest)
1 | > xgroup create venom:stream consumer-group-latest $ |
XREADGROUP GROUP
语法规则:XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]
- group:消费组名称
- consumer:消费者名称
- count:读取数量
- milliseconds:阻塞毫秒数
- key:队列名称
- ID:消息 ID
读取消费组中的消息
1 | > xreadgroup group consumer-group-earliest consumer-01 count 1 streams venom:stream > |
应用场景
- 消息队列